一早发现…昨晚交的自动分批push到github的任务挂了…报错没有权限或者库不存在.. 应该不会没有权限的, 所以检查了一下库..果然挂了…
This repository has been disabled.
Access to this repository has been disabled by GitHub staff due to excessive use of resources, in violation of our Terms of Service. Please contact support to restore access to this repository. Read here to learn more about decreasing the size of your repository.
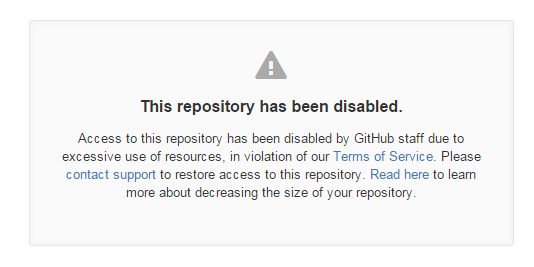
当时的库大小是50G多点, (显示占用和大小为55,000,000,000+), 包括git的对象文件的话130G吧. 所以也好, 测试了Github的上限占用空间容忍度…删掉重建就好了.
主运行脚本
通过while循环反复抓取. 这里注意:
- 修改输出result.log 输出名字, 很重要, 因为输出到这个文件, 然后每次循环时会从中抓取最后一次成功的编号用于下次启动
- 第一次运行时, 需要取消掉其中一句注释, 往输出文件写入第一次运行的编号.
- 自行修改ISSN号, 最大每次运行
crossget.sh时最大抓取文献数量(方便一定数量后休息) - while循环中还有一段注释, 是原来运行时检查抓取数量, 然后打包传去另一个服务器的(因为抓取服务器空间很少..). 首先需要实现免密码登录(ssh-keygen,产生
id_rsa.pub, 然后写到服务器端.ssh/authorized_keys 文件末端,自己搜一下..).
#! /bin/bash
ISSN="1091-6490"
maxatime="300"
logfile="result.log"
### When first time to run, cancel commend the following:
#echo "## Now Get PDF for doi: 10.1073/pnas.052143799 Done! Next: 0" > $logfile
while [ 'a' = 'a' ];do
nextitem=`grep "Done" $logfile | tail -n 1 |awk '{print $10}'`
if [ -z $nextitem ];then
nextitem="0"
fi
./crossget.sh $ISSN $nextitem $maxatime | tee -a $logfile
#pdfcount=`ls Done/*.pdf | wc -l`
#if [ $pdfcount -gt 300 ];then
#ts=`date +%s`
#cd Done
#tar -cz --remove-files -f PNAS_${ts}.tar.gz *.pdf
#scp PNAS_$ts.tar.gz user@server_name:~/PATH
#rm PNAS_$ts.tar.gz
#cd ..
#else
sleep 300
#fi
done
运行抓取python脚本的外部
因为需要抓取输出记录给主运行脚本, 所以嵌套了一个脚本, 然后猪脚本运行他后顺带输出到指定log文件给主脚本分析.
使用不用作任何修改. 其中一个注释掉的循环, 是以前没有主脚本while循环控制时用于控制起始和抓取数量, 抓取范围的. 已废弃
#! /bin/bash
# Use as crossget.sh ISSN start_number max_try_a_time
if [ ! -z $1 ];then
ISSN=$1
else
echo "No ISSN is given!"
exit 1
fi
start=0
if [ ! -z $2 ];then
start=$2
fi
maxatime=300
if [ ! -z $3 ];then
maxatime=$3
fi
##127499 total
#for i in `seq $start 100 10500`;do
python getjournalPDF.py $ISSN $start $maxatime
mv *.pdf Done
#done
主抓取文献Python脚本
根据情况需要修改其中第一个函数urlcovert, 用于将抓到的doi对应url转为pdf的url.
建议进一步修改每次抓取后时间间隔, 防止被block, 我就被Bioinformatics block掉了..抓pdf链接抓回来是html内容…换另一台机子就OK..
调用基本的库urllib2和json而不是requests, 所以移植性增强.
#! /usr/bin/env python
# Usage: python script.py issn [,offset, maxresult]
import urllib2,os,sys,json,gc
issn=""
offset=0
maxresult=500
def urlcovert(url):
# for PNAS, Oxford journal
return url+'.full.pdf'
# For Plos One
#url=url.replace('article?id','article/asset?id')
def quotefileDOI(doi):
'''Quote the doi name for a file name'''
return urllib2.quote(doi,'+/()').replace('/','@')
def unquotefileDOI(doi):
'''Unquote the doi name for a file name'''
return urllib2.unquote(doi.replace('@','/'))
def decomposeDOI(doi, url=False, outdir=False, outlist=False, length=5):
'''Decompose doi to a list or a url needed string.
Only decompose the quoted suffix and prefix will be reserved.
Note that dir name can't end with '.', so the right ends '.' will be delete here.
Note that only support standard doi name, not prefix@suffix!
If error, return "".
Default, decompose to a dir name (related to doi).
If url, output url string (containing quoted doi name)
If outdir, output string for directory of doi
If outlist, output to a list including quoted doi'''
doisplit=doi.split('/',1)
if (len(doisplit) != 2):
print "Error Input DOI:", doi.encode('utf-8')
return ""
prefix=doisplit[0]
suffix=quotefileDOI(doisplit[1])
lens=len(suffix)
# Too short suffix
if (lens<=length):
if outdir:
prefix+"/"
if (url):
return prefix+"/"+prefix+"@"+suffix
elif (outlist):
return [prefix,suffix]
else:
return prefix+"/"
# Decompose suffix
layer=(lens-1)/length
dirurl=[prefix]
for i in range(layer):
dirurl.append(suffix[i*length:(i+1)*length].rstrip('.'))
if (outdir):
"/".join(dirurl)+"/"
elif (url):
return "/".join(dirurl)+"/"+prefix+"@"+suffix
elif (outlist):
dirurl.append(suffix[(lens-1)/length*length:])
return dirurl
# Default return dir string for doi
else:
return "/".join(dirurl)+"/"
def is_oapdf(doi,check=False):
'''Check the doi is in OAPDF library'''
if (check and "/" not in doi and "@" in doi):
doi=unquotefileDOI(doi)
try:#urllib maybe faster then requests
r=urllib2.urlopen("http://oapdf.github.io/doilink/pages/"+decomposeDOI(doi,url=True,outdir=False)+".html")
return (r.code is 200)
except:
return False
def findPDFbyISSN(issn,maxresult=None, step=100, offset=0):
'''Find PDF by ISSN based on search result from crossref'''
# may be improve to not only issn..
if (not issn):return
needurl="http://api.crossref.org/journals/"+issn+"/works"
j1=needurl+"?rows=1"
r=urllib2.urlopen(needurl)
j=json.loads(r.read())
r.close()
total=int(j['message']['total-results'])
if (not maxresult or maxresult <=0 or maxresult>total):
maxresult=total-offset
prefix="?rows="+str(step)
maxround=maxresult/step+1
offsetcount=offset
for i in range(maxround):
params=prefix+"&offset="+str(step*i+offset)
try:
r=urllib2.urlopen(needurl+params)
js=json.loads(r.read())
for j in js['message']['items']:
doi=j.get("DOI","")
if (is_oapdf(doi)):
print "#####################################",offsetcount,"####################################"
print "## Now Has OAPDF for doi:",doi,"Done! Next: "+str(offsetcount+1)
offsetcount+=1
continue
if (doi):
print "#####################################",offsetcount,"####################################"
print "## Now Get PDF for doi:",doi,
#url="http://dx.doi.org/"+doi
url="http://38.100.138.163/"+doi
r2=urllib2.urlopen(url,timeout=20)
urlreal=r2.url
rpdf=urllib2.urlopen(urlcovert(urlreal),timeout=20)
with open(quotefileDOI(doi)+".pdf",'wb') as pdf:
pdf.write(rpdf.read())
r2.close();rpdf.close()
if (os.path.exists(quotefileDOI(doi)+".pdf")):
print "Done! Next: "+str(offsetcount+1)
else:
print "Fail...."
r.close()
sys.stdout.flush()
offsetcount+=1
except:
pass
gc.collect()
if __name__ == "__main__":
if (len(sys.argv)<2):
exit()
elif (len(sys.argv)>=2):
issn=sys.argv[1]
if (len(sys.argv)>=3):
offset=int(sys.argv[2])
if (len(sys.argv)>=4):
maxresult=int(sys.argv[3])
#issn="1091-6490"
#total=127499
findPDFbyISSN(issn,offset=offset,step=100,maxresult=maxresult);
后台监控打包和上传的脚本
直接nohup CheckDone.sh & 扔后台就好了,log在nohup.log
#! /bin/bash
while [ 'a' = 'a' ];do
pdfcount=`ls *.pdf | wc -l`
if [ $pdfcount -gt 300 ];then
ts=`date +%s`
tar -cz --remove-files -f PNAS_${ts}.tar.gz *.pdf
scp PNAS_$ts.tar.gz user@server_name:~/PATH
rm PNAS_$ts.tar.gz
else
# Check intertime
sleep 5
fi
done